
Manufacturing companies in the DACH Mittelstand are sitting on a great deal of valuable data, and almost none of them are using it well. I've spent the last few months talking to plant managers, controllers, and owners across the region, most recently at Hannover Messe last week, and the pattern is consistent. The data exists. They know it exists. They can't really use it.
The reasons are more interesting than they first appear, and I think they're worth working through carefully, because the popular framing (that manufacturers are too slow, too risk-averse, too attached to legacy) gets the situation almost exactly backwards.
The problem isn't missing data
A modern production line generates a lot of useful telemetry data. Machine state, cycle times, energy use, material flow, quality reads, operator sign-offs. Most of it is sitting somewhere already: in a SCADA system, an ERP module, a spreadsheet a controller updates every Friday afternoon. The data is rarely missing. Most manufacturers already have the data. It is just split between machine data, ERP data, warehouse data, and spreadsheets, so the full picture is hard to see.
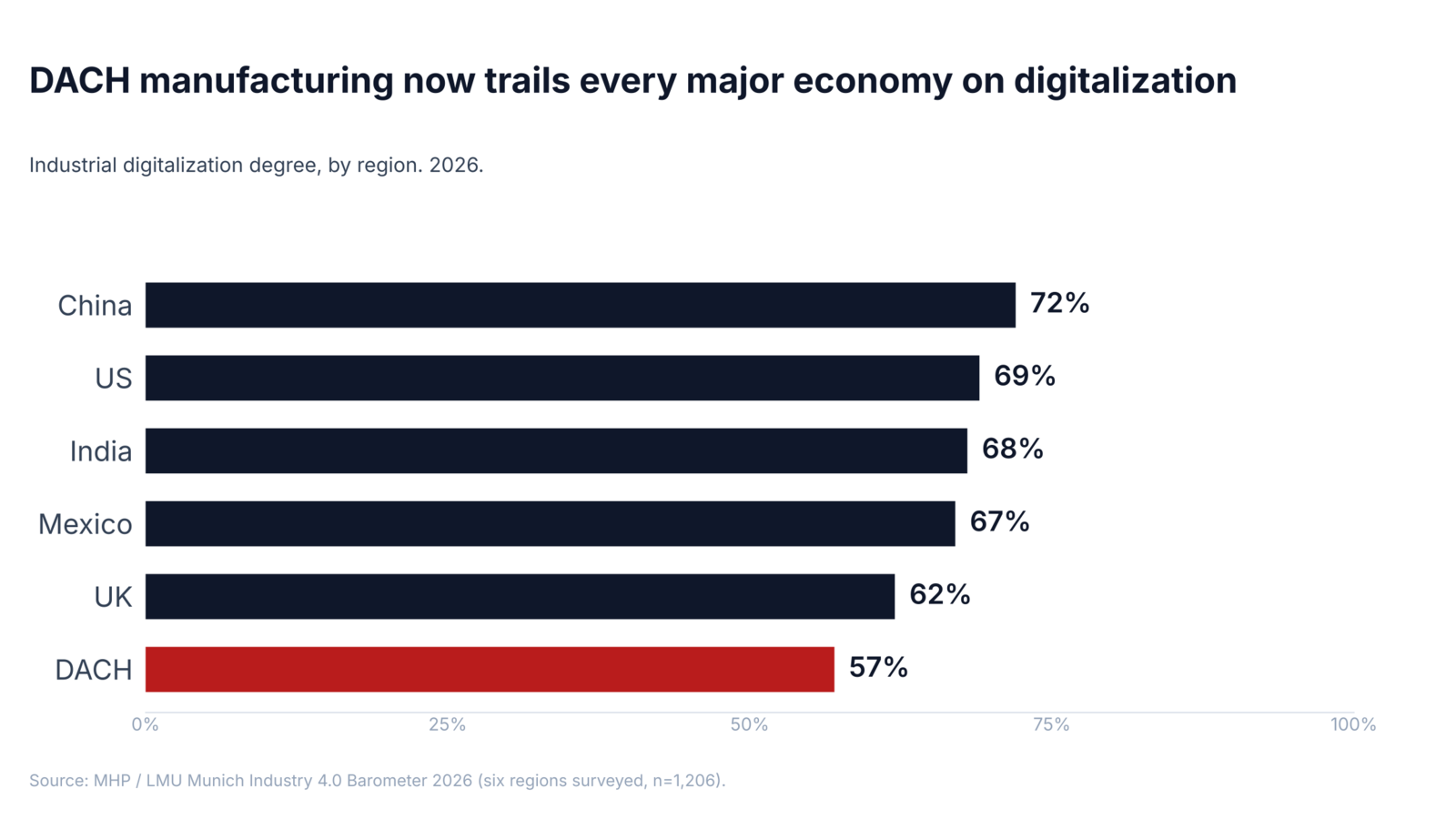
A recent ARC Advisory Group survey of industrial decision-makers found that 63% describe an "Industrial Data Fabric" as critically important, and 63% say "decoupling data from software" is critically important (ARC Advisory Group, 2026). They have language for what's missing. Redwood Software's 2026 outlook found that 78% of manufacturers have automated less than half of their critical data transfers, and only 40% have automated exception handling (Redwood, 2026). The MHP / LMU Munich Industry 4.0 Barometer puts DACH digitalization at 57% and stagnating, while the global average has climbed to 68% (MHP / LMU, 2026).

So manufacturers know there is an asset, and they have named the problem. And by most measures, the gap keeps getting wider every year.
What that data is actually worth
DACH manufacturing SMEs typically run on net margins in the low single digits, often somewhere between 3% and 6% depending on the sub-sector. At a 4% net margin, a 5% reduction in production cost more than doubles profit. A €10M metalworking shop netting €400k a year can unlock €200k to €300k just by getting visibility into where the money is actually going.
Some of the use cases are genuinely simple, in the sense that they don't require AI, a digital twin, or replacing the ERP.
Take Overall Equipment Effectiveness (OEE), the standard industry measure of how productively a machine runs against its full potential. Industry benchmarks put world-class OEE at 85% and typical manufacturing OEE closer to 60% (Lean Production Inc.). The gap between actual operating performance and best-in-class is typically worth 5% to 15% of total production cost.
Energy is similar. A meaningful share of an industrial electricity bill, often half or more, runs when nothing is producing. Lights, compressors, HVAC, machines in idle. Once kilowatt-hours can be attributed to specific lines, products, and shifts, typical savings sit between 10% and 25% of energy spend. That tracks the lower end of the US Department of Energy's submetering best-practice benchmarks, which report ranges of 15% to 45% (FEMP Metering Best Practices Guide, PNNL-23892). With German industrial electricity prices in the order of 18 ct/kWh, even the conservative end adds up quickly.
Food and beverage producers tend to have a different version of the same problem: producing more than they sell, and writing the rest off. Connecting production planning to actual demand and shelf life is one query against the ERP and one against the sales orders. Recoverable waste is typically 20% to 40%.
None of this is novel. None of it requires AI. It requires existing data to be connected well enough that simple questions can be answered reliably.
So why isn't this happening?
It isn't for lack of trying. Almost every manufacturer I have spoken to has run some version of a project to clean up reporting, consolidate data across sites, or build a central dashboard. The pattern that emerges is fairly consistent: a handful of Power BI dashboards covering the most important reports, an ERP module that does what it does, and Excel as the clunky connective tissue between everything else. That answers the top few questions. Every new question requires a fresh round of CSV exports, manual joins, and somebody's evening. Building anything more durable means a multi-month consulting engagement that the budget can't justify against a Power BI licence already covering the top five reports.
The dissonance shows up clearly when people are asked directly. KPMG's 2026 industrial-manufacturing report finds that 83% of executives believe they are building strong data foundations, while 76% in the same survey say unreliable data is a top risk to their AI ambitions (KPMG, 2026). The two answers are contradictory, and they come from the same people in the same survey.
The reality of digitalization projects
The standard explanation for the gap above (that manufacturers are too slow, too risk-averse, too attached to legacy) is the explanation that gets you a transformation programme. I don't think it's true.
The explanation I keep hearing from the people actually running these companies is straightforward: they have looked at what's on offer and the math doesn't work.
A serious data project from one of the usual platforms (Databricks, Snowflake, an SAP S/4 migration) typically lands at €100k or more in the first year, with six to twelve months before anything useful ships. Those tools are sized for companies that already have a full-time data engineering function: platform-grade engineers, a dedicated team, a governance layer. A 200-person manufacturer in Schwäbisch-Hall has none of that. They have a controller with a Power BI licence and a part-time IT person who keeps the network running. For that company, Databricks is the wrong order of magnitude in cost, time, and required headcount.
A second category of solutions sits at the ecosystem level: GAIA-X, Catena-X, Manufacturing-X, the Asset Administration Shell. The promise is understandable. These initiatives try to create common standards and trusted data spaces so manufacturers, suppliers, customers, and software providers can exchange industrial data more easily: product data, CO2 footprints, quality records, traceability information, digital product passports. In theory, that reduces one-off integrations and gives European industry a more sovereign data infrastructure.
I don't want to disparage the people working on these. They are trying to solve real problems. But for a Mittelstand manufacturer, the timing and the value proposition are different. Many suppliers will probably be pulled into these frameworks by large customers eventually. That does not mean the framework solves today's problem: scattered internal data, manual reporting, and no easy way to answer operational questions.
The track record also matters. GAIA-X launched in 2019 with hundreds of millions of euros in direct German federal funding behind it, pitched as Europe's sovereign answer to AWS. By 2021 some early member companies were withdrawing, citing bureaucracy and slow delivery (CIO / Handelsblatt, 2021). By 2024 the hyperscalers had quietly joined the board. By early 2025 EuroStack had published a piece called "Chronicle of a Failure Foretold". The first company to receive the highest-tier GAIA-X certification got it in late 2025, six years after the initiative launched.

And even when the budget and architecture line up, the work falls on one person who already has a full-time job. They usually give up before the project ships.
The honest version is that the tools currently on offer were not built for the kind of company most of the manufacturing world consists of. Only 30% of Mittelstand companies have actually completed their digitalization projects (KfW / ZEW, 2026). Manufacturers are not ignoring the problem. They are looking at the available options and finding that the business case does not hold.
Why we're building Beetl
Most of what I've described above is the reason we're building Beetl, and the shape of what we're building follows from it.
We are trying to build a pragmatic data analytics solution a Mittelstand manufacturer can actually use right now: 50 to 500 employees, one to ten sites, no full-time data engineering team, an aging stack of systems that store data under different schemas, and one or two technically capable people keeping reporting alive on the side.
The product is built around getting useful answers within a few weeks of getting started. We aim for the eighty percent of value that can be delivered quickly, then expand only where the additional complexity still pays for itself. Where we have to integrate with the EU industrial-data ecosystem (Catena-X, AAS, OPC UA) we do it as adapters that emit the right format on demand. We don't ask the customer to adopt a framework as their architecture, sit on a working group, or certify anything.
We use LLMs as an interface layer, not as the source of truth. Their real value is that operators can describe intent in plain language: what a machine means, how a production step works, which number looks wrong, what question they are trying to answer. The system can turn that intent into structured mappings, queries, and checks against the underlying data. That is the part we automate.
Portability matters. We build on open-source technologies where possible and make sure the customer can keep using their data outside Beetl.
The simplest way to describe what we do is: we help manufacturers use the data they already have to recover margin that's currently invisible to their P&L.
For a concrete worked example of the kind of question a connected data layer makes answerable, see Can you see per-order margin while the shift is still running?.