
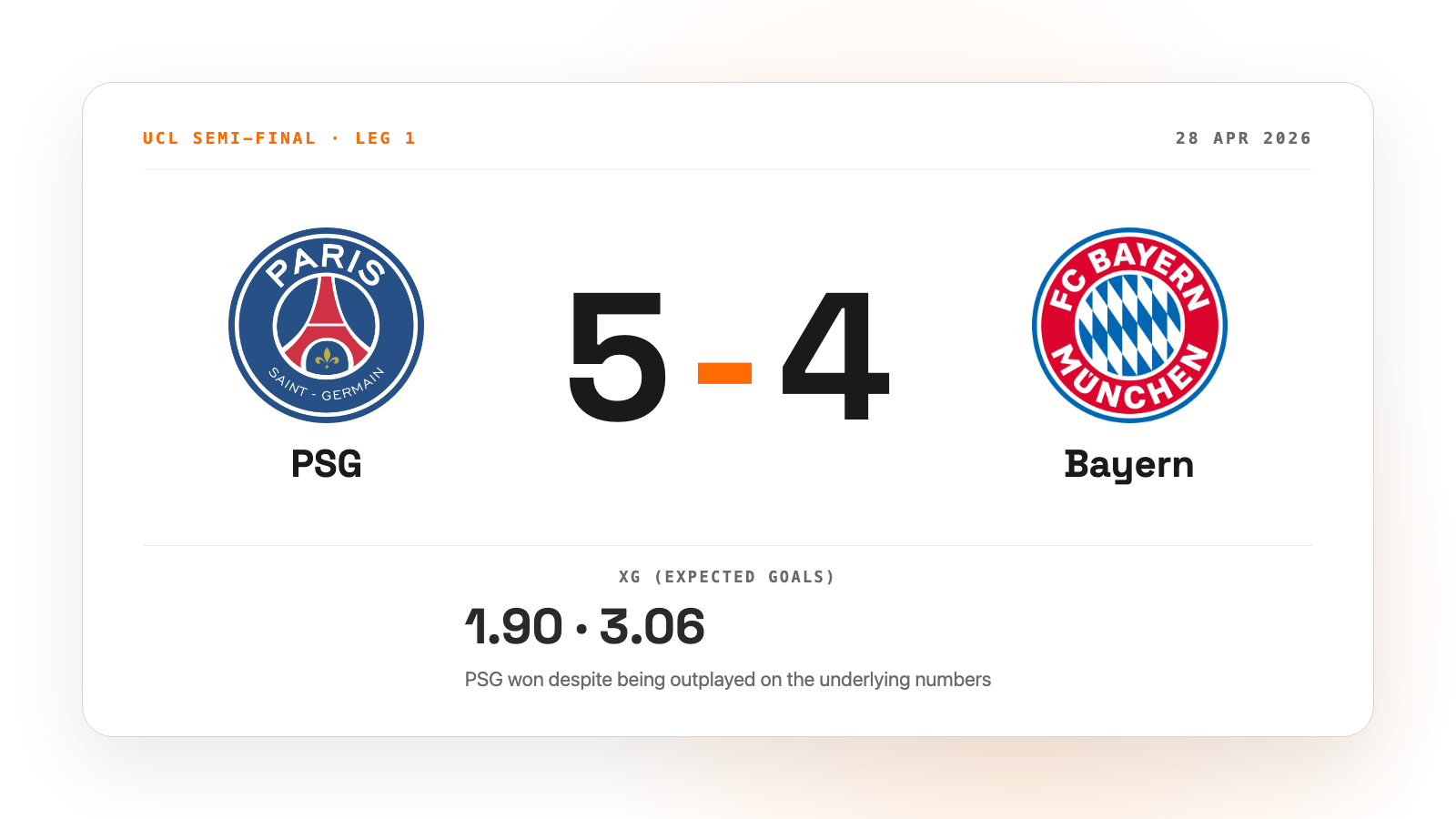
Champions-League-Knockout-Spiele enden normalerweise nicht 5:4. Das Halbfinal-Hinspiel zwischen PSG und Bayern im April schon. Bayern hatte 57 % Ballbesitz, ein xG von 3,06 gegenüber PSGs 1,90 und sechs Big Chances gegenüber zwei von PSG. Trotzdem gewann PSG. Ich bin in die Daten gegangen, um zu verstehen, was da passiert sein könnte.
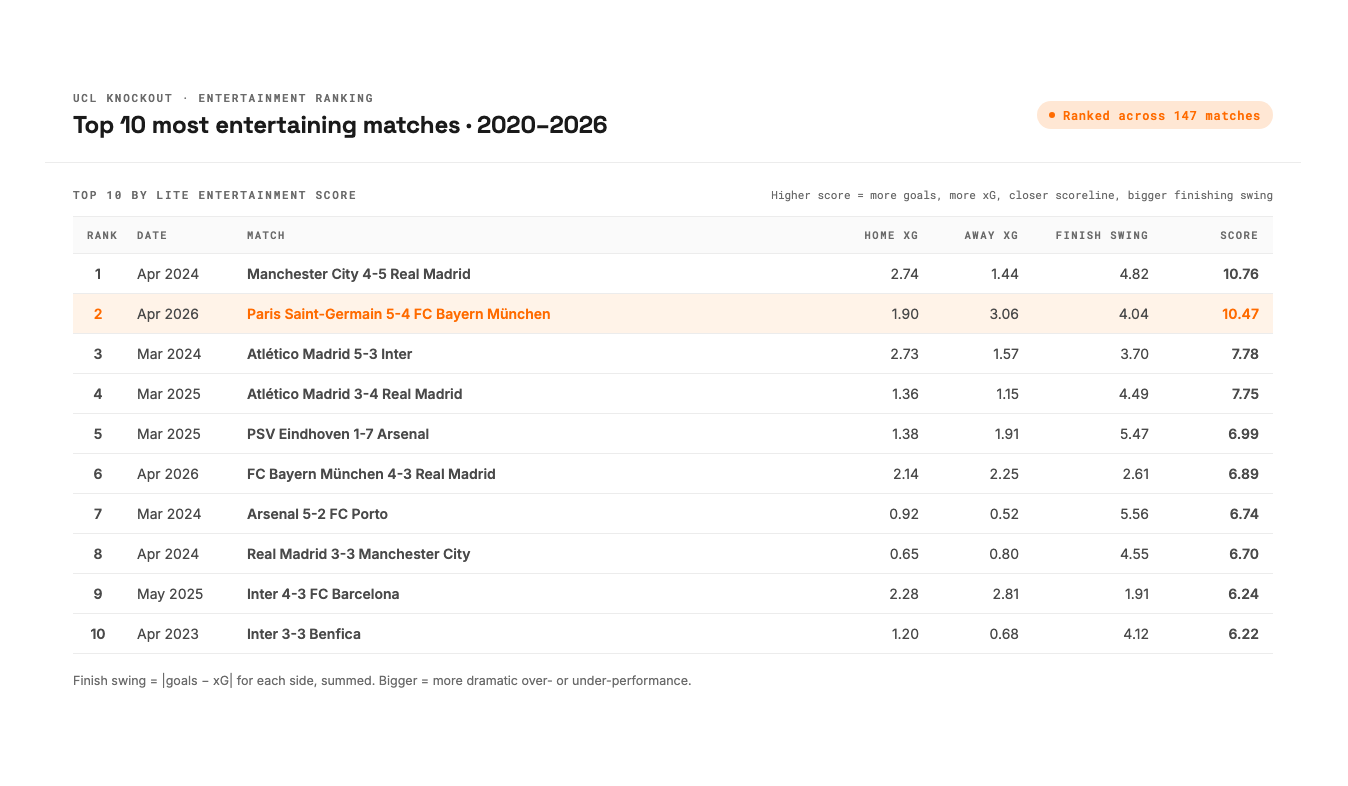
Selbst die Daten sagen: Dieses Spiel war das zweitunterhaltsamste Champions-League-Knockout-Match der letzten sechs Saisons. Ich habe alle 147 UCL-Knockout-Spiele seit 2020 im Datensatz nach Gesamtzahl der Tore, total xG und der Enge des Spielstands bewertet. Nur Manchester City 4:5 Real Madrid im April 2024 lag noch darüber.
Vor dem Rückspiel war meine Frage nicht wirklich, wie gut PSG ist. Die Frage war, ob das Ergebnis aus dem Hinspiel wiederholbar war, oder ob Bayern beim nächsten Mal einfach seine Chancen verwerten würde. Gab es etwas Strukturelles, das PSG einen Vorteil gab? Oder war das 5:4 einfach High-variance Noise, der keine weiteren 90 Minuten überlebt? Um das zu beantworten, musste ich mir ansehen, wo PSGs Angriff eigentlich herkam, wer ihn getragen hat und ob irgendetwas daran reproduzierbar war.
Was nötig war, um diese Fragen zu beantworten, hat mich am Ende mehr überrascht als die Antworten selbst.
Runde eins: Was der erste Blick auf die Zahlen sagte
Meine erste Analyse ging am Tag vor dem Rückspiel auf LinkedIn online. Fünf Dinge stachen heraus:
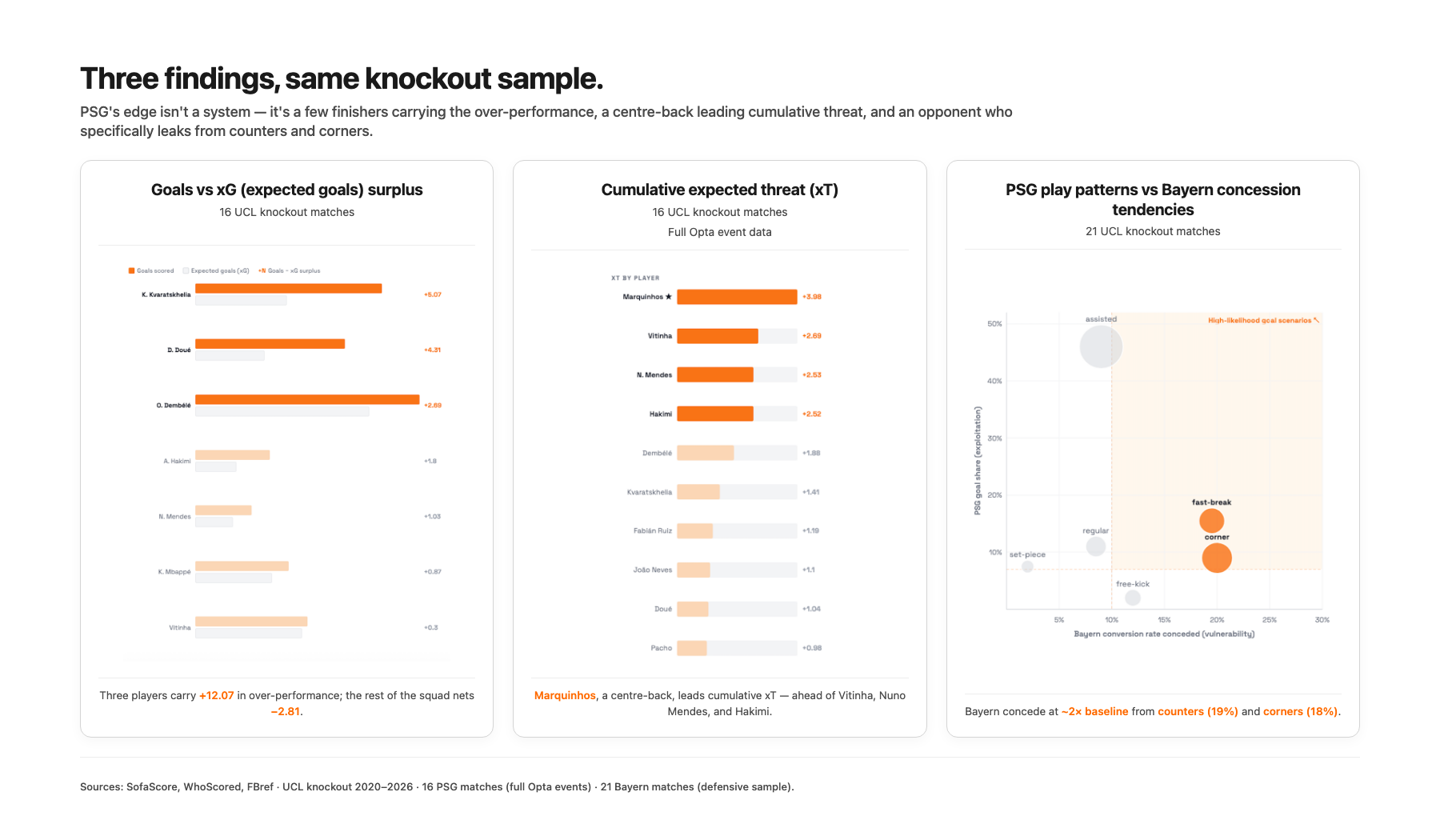
PSG overperformt xG um +0,59 Tore pro Knockout-Spiel. Über die damals 16 Spiele im Sample erzielten sie seit über einem Jahr konstant mehr Tore, als die zugrunde liegenden Zahlen erwarten ließen.
Drei Spieler tragen 75 % der Overperformance. Kvaratskhelia +5,07, Doué +4,31, Dembélé +2,69, zusammen +12,07 über das Knockout-Sample. Der Rest des Kaders underperformt zusammen um −2,81. Das Muster "wir schlagen bessere Teams nach xG" war in Wirklichkeit eher "zwei oder drei unserer Finisher sind on fire."
Marquinhos ist PSGs höchster kumulativer xT-Contributor. Vor Vitinha, Nuno Mendes, Hakimi und den Wingers. Ein Innenverteidiger an der Spitze der Threat-Creation-Tabelle war genau die Art Finding, die auffällt. Der Pushback eines Freundes später in der Analyse hat mich gezwungen, das sauber auseinanderzunehmen.
Pressing variiert je nach Matchup. PSGs PPDA (Passes per Defensive Action, eine Metrik dafür, wie hoch und intensiv gepresst wird) lag gegen Monaco bei 5,3: ein sehr intensives Pressing mit Ballgewinnen hoch am Feld. Gegen Bayern im Hinspiel lag der Wert bei 17,1, dem tiefsten Sit-back im gesamten 16-Spiele-Sample. Enrique scheint das Pressing-Level nach Gegner zu wählen.
Bayern ist besonders anfällig bei Countern und Ecken. Ihr Defensivprofil über 21 UCL-Knockout-Spiele sah insgesamt ungefähr liga-durchschnittlich aus, aber sie kassieren doppelt so häufig wie die Baseline nach Kontern (19 % Conversion gegen sie) und Ecken (18 %). Die Schwäche war konzentriert, nicht allgemein.
Meine Prediction für Leg 2 war: PSGs wahrscheinlichstes Tor-Muster wäre Open-play-Volume von Kvaratskhelia oder Doué, oder ein Counter, der Bayerns Set-piece-Schwäche ausnutzt.
Im Rückspiel spielte Bayern zuhause 1:1, outperformte PSG beim xG erneut (1,41 zu 1,06) und schied insgesamt mit 5:6 aus. Über beide Spiele zusammengenommen war Bayern nach den zugrunde liegenden Zahlen besser und verlor trotzdem das Tie. Genau dieses Muster hatte PSG die ganze Saison über immer wieder gezeigt.
Wenn die Analyse dort aufgehört hätte, hätte ich das als gutes Ergebnis verbucht. Dann las mein guter Freund Benjamin Turk den LinkedIn-Post und widersprach der überraschendsten These.
Mein Freund hatte recht mit dem Pushback, die Antwort war nur nuancierter
Sein Einwand, paraphrasiert: "Marquinhos hat in dieser Kampagne zwei Tore und null Assists. Auf dem Platz sieht er nicht wie ein Creator aus. Wie kann er dann bei Expected Threat Nummer eins sein?"
Mein erster Impuls war, die Metrik zu verteidigen. Genau das ist der falsche Move. Wenn eine Zahl mit dem kollidiert, was jemand beim genauen Zuschauen sieht, muss die Zahl erklärt werden. Also bin ich zurück in die Daten gegangen und habe drei andere Fragen gestellt.
Runde 1: Wo auf dem Feld entsteht der xT?
Ich habe Marquinhos' xT-Beitrag danach aufgeteilt, in welcher Zone jede Aktion begann:
- Defensive Third (start_x unter 35 Meter): 3,2 %
- Middle Third (35 bis 70 Meter): 18,8 %
- Attacking Third (über 70 Meter): 78,0 %
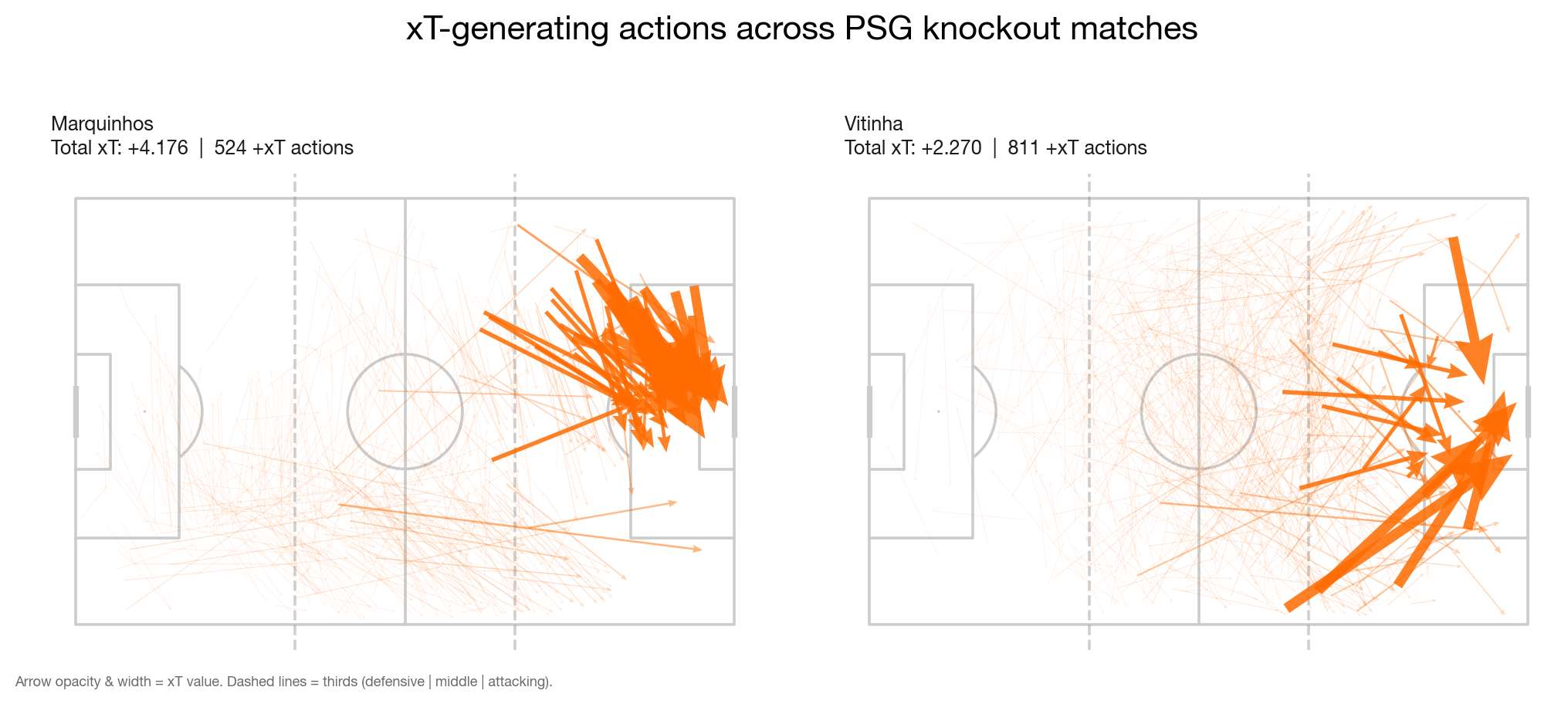
Was auch immer Marquinhos tat: Es waren keine line-breaking Pässe aus der Tiefe. Die Heatmap seiner xT-Ursprünge clusterte eng rechts an der Strafraumkante, weit in der gegnerischen Hälfte.
Der Mechanismus meines Freundes war falsch, aber sein Instinkt, dass etwas nicht stimmte, war richtig. Nur in die andere Richtung.
Runde 2: Welche Spiele haben das getrieben?
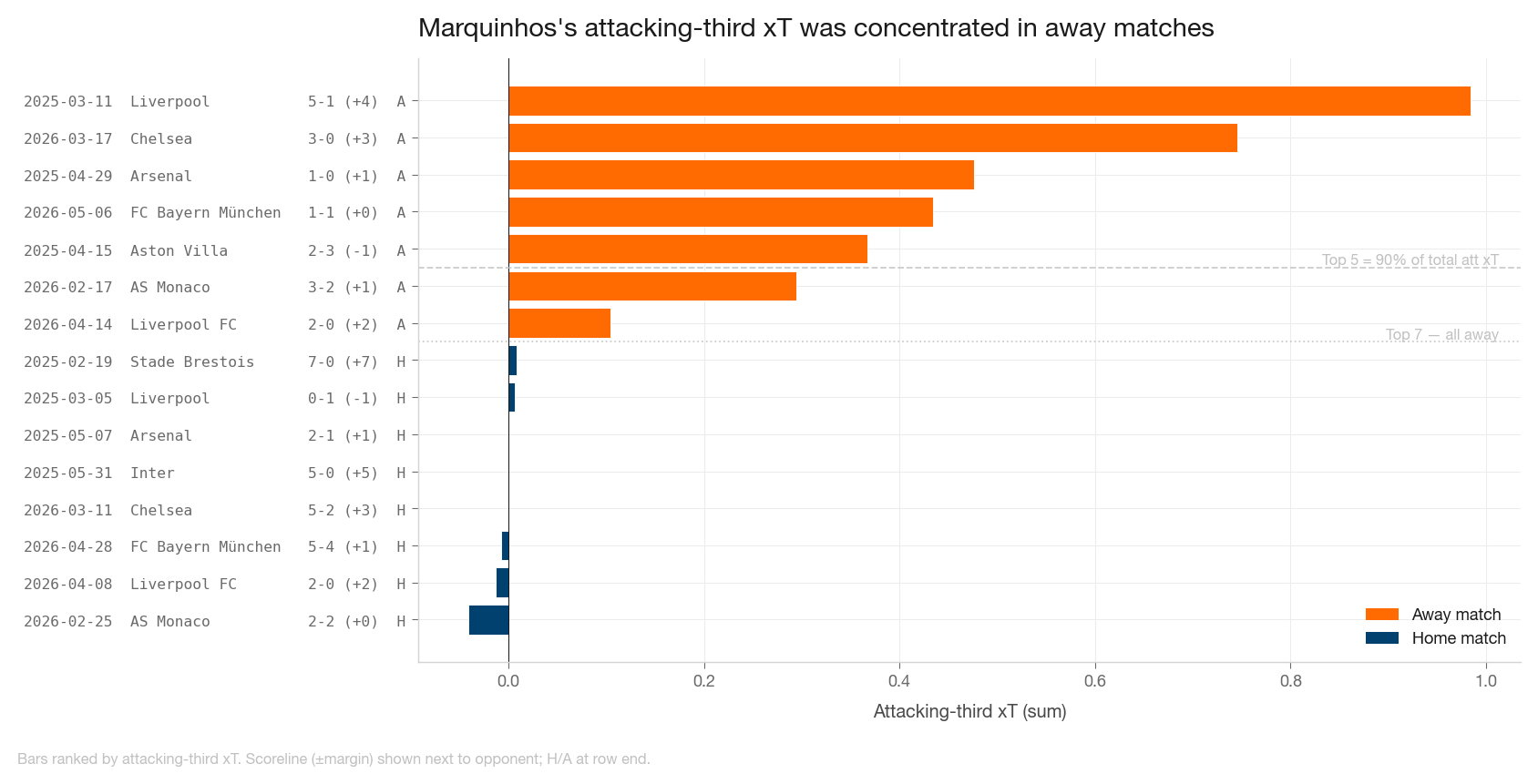
Wenn man Marquinhos' Attacking-third-xT Match für Match aufteilt, sieht man eine extreme Konzentration:
- Top 5 Matches tragen 92 % des Gesamtwerts
- Bottom 10 Matches zeigen praktisch keinen Attacking-third-Beitrag
- Top 7 Matches nach Attacking-third-xT waren alle Auswärtsspiele
Die Höhe des Sieges hatte keine sinnvolle Korrelation mit der Metrik, der Spielort aber schon. In Auswärtsspielen, in denen PSG Ballbesitz dominierte, rückte ein Innenverteidiger in den rechten Halbraum auf und sicherte den Ball an der Strafraumkante. Durch viele kurze Pässe in High-value-Zonen sammelte sich xT Stück für Stück. Keine Creator-Rolle, sondern ein Positionsartefakt davon, wie PSG genau diese Spiele spielte.
Runde 3: Was passiert, wenn ich die Metrik ändere?
xT misst, ob eine Aktion den Ball in eine gefährlichere Zone bewegt. Aber die Aktion muss nicht zu einer Chance, einem Schuss oder einem Tor führen. Also habe ich vier Metriken ergänzt, die genau näher daran sind:
- KeyPasses: Pässe, die direkt zu einem Schuss führen
- BoxEntries: Pässe von außerhalb in den Strafraum
- ProgressivePasses: Vorwärtspässe über 10 Meter oder mehr
- FinalThirdEntries: Pässe vom mittleren ins letzte Drittel
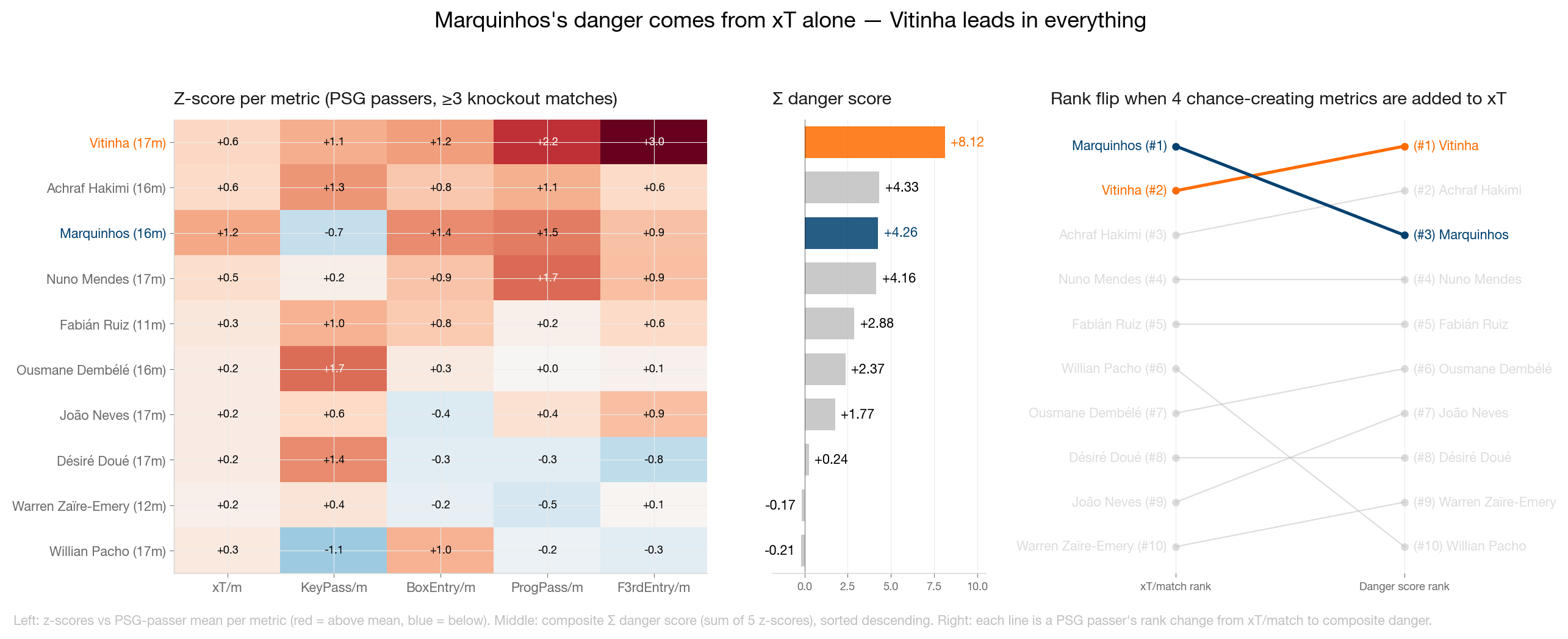
Ich habe jede Metrik über Spieler mit drei oder mehr Matches z-standardisiert und zu einem Composite-"Danger"-Score addiert. Das Ranking drehte sich: Vitinha +8,03, Hakimi +4,30 als nächster PSG-Spieler, Marquinhos nur geteilt Dritter.
Raw KeyPass Counts über 17 Spiele erzählten dieselbe Geschichte: Marquinhos 5, Vitinha 27, Hakimi 28, Dembélé 32.
Nach Creation-Metriken sitzt Marquinhos eher am unteren Ende der Rotation. Nach aggregiertem xT führte er das Team an. Beide Zahlen sind real, und beide beschreiben denselben Spieler, der unterschiedliche Dinge tut.
Die drei Runden waren inkonsistent genug, dass das ursprüngliche Framing "Marquinhos ist Nummer eins" komplett davon abhing, welche Metrik ich ausgewählt hatte.
Nimm eine andere Metrik, und die Antwort kippt. Das ist eigentlich die Story.
Was ich über das Matchup wirklich gelernt habe
Bayern hat PSG zweimal nach den zugrunde liegenden Zahlen ausgespielt. xG, xT, Dangerous-player Counts und Dribble Volume lagen über das Tie hinweg alle bei Bayern. PSGs Edge ist keine taktische Überlegenheit; es ist Finishing-Konzentration bei zwei oder drei Spielern, plus eine defensive Struktur, die gut genug ist, um einen Gegner auszuhalten, der mehr kreiert.
Vitinha, nicht Marquinhos, ist der eigentliche Motor. Er führt PSG über 17 Knockout-Spiele bei KeyPasses, Progressive Passes und Final-third Entries an. Unter jedem Composite, der Chance-Creation-Metriken einbezieht, war Vitinha von Anfang an die Antwort.
War das Ergebnis aus dem Hinspiel also wiederholbar? Wahrscheinlich nicht in genau dieser Form. Das 5:4 war High-variance Finishing auf einer strukturellen Unterlegenheit, und das 1:1 im Rückspiel lag näher an dem, was die zugrunde liegenden Zahlen nahelegten. PSGs Vorteil ist nicht zuverlässig reproduzierbar. Er funktioniert, solange ihre drei Finisher heiß bleiben und darüber hinaus ihr Spielniveau halten.
Was es wirklich brauchte, um diese Fragen zu beantworten
Die nützlichsten Antworten kamen aus der zweiten, dritten und vierten Frage. Die erste war der einfache Teil. Dass alle drei Follow-ups an einem Abend passiert sind, statt drei weitere Wochenenden Plumbing zu brauchen, lag daran, dass das Plumbing schon fertig war.
Alles jenseits der Oberfläche brauchte drei verschiedene Quellen, die kombiniert werden mussten. Jede allein ist stark, aber ohne die anderen beiden nicht genug:
- SofaScore für Schüsse und xG über 147 Knockout-Matches aus sechs Saisons, also das Vergleichs-Sample.
- WhoScored für action-by-action Event Streams über die 17 PSG-Knockout-Matches. Jeder Pass, jedes Dribbling, jedes Tackling mit Koordinaten und Qualifiern (KeyPass, ShotAssist, Longball). Raw Events haben über 30 Spalten; SPADL, das standardisierte Action-Format, komprimiert das auf ungefähr 15.
- FBref für season-level Player Stats. Kontext, den die Matchdaten nicht abbilden.
Jede Quelle hat andere Match-IDs, nennt dieselben Spieler unterschiedlich ("Doué" vs. "Désiré Doué") und rate-limited so hart, dass man aggressiv cachen muss oder Stunden verliert. Der größte Teil der Setup-Zeit geht genau dort hin.
Jede erfolgreiche Aktion wird dann mit einem xT-Modell (Expected Threat) bewertet, also einem Wert von 0 bis 1 dafür, wie viel näher die Aktion den Ball an ein Tor gebracht hat. Das Ergebnis ist eine einheitliche Tabelle: Koordinaten, Spieler, Team, Match, Score, xT. Alles in diesem Post sind ein oder zwei Queries dagegen.
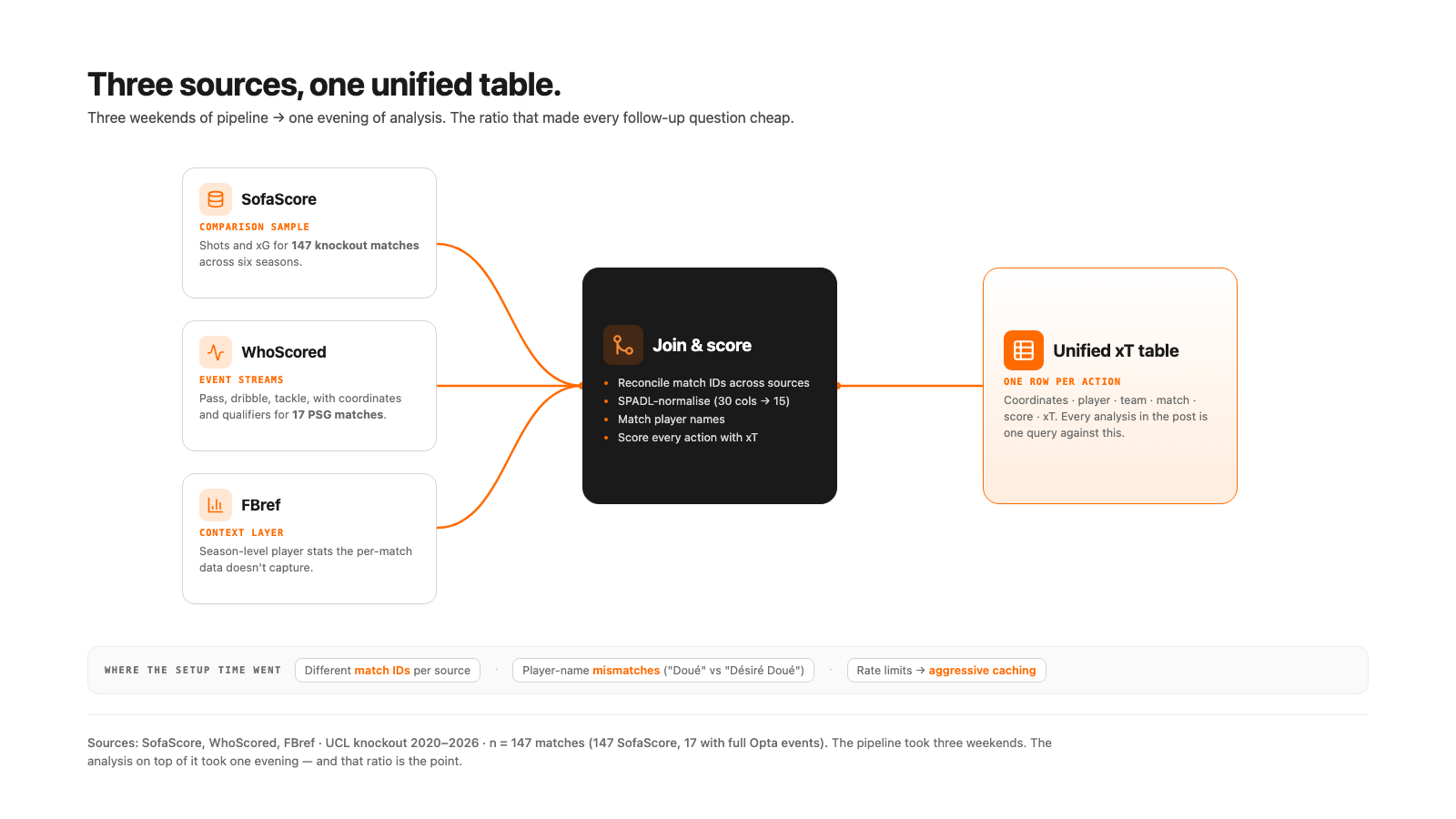
Die Pipeline zu bauen dauerte drei Wochenenden. Die eigentliche Analyse darauf dauerte einen Abend. Dieses Verhältnis ist der Punkt.
Warum diese Art Analyse heute nicht skaliert
Jede Follow-up-Frage, die ich gestellt habe, brauchte eine andere Form derselben Daten: Aktionen verbunden mit Pitch Zones, dann mit Match-Metadaten, dann mit Raw-event-Qualifiern. Derselbe Datensatz, drei verschiedene Shapes. Jede Frage dauerte ungefähr eine Stunde, nachdem alles an einem Ort war. Das Setup davor dauerte eine Woche.
Diese Diskrepanz beim Data Wrangling ist nicht spezifisch für Fußball. Ein Plant Manager fragt, warum die Overall Equipment Effectiveness diesen Monat gefallen ist, und bekommt eine Zahl zurück. Die Follow-ups — ist es Shift B? Linie 3? nur dienstags nach der Wartung? — brauchen dieselben operativen Daten, aber drei andere Schnitte, mit derselben Art Plumbing: verschiedene Quellen (MES, ERP, Quality, Maintenance), verschiedene IDs (Work Order, Batch, Maschine), verschiedene Schemas. Ohne Data Team bleiben die meisten SMEs bei der ersten Antwort stehen. Die zweite braucht SQL, Python oder eine Woche unbezahlte Stunden.
Genau diese Lücke zwischen der ersten und der zweiten Antwort ist das Problem, das es zu lösen lohnt.
Was wir bauen
Beetl ist für die zweite, dritte und vierte Frage. Man legt operative Dateien an einem Ort ab — Produktionslogs, ERP-Exporte, Qualitätsdaten, Wartungsdaten — und die Joins, das Cleaning und die Auflösung von Namen und IDs passieren in einer Chat Session. Diese Schritte werden als wiederholbare Pipeline gespeichert, sodass die Daten des nächsten Monats automatisch durchlaufen. Wenn die nächste Frage kommt, stellt man sie in normaler Sprache, und das System kümmert sich um die Re-joins.
Die Football-Pipeline dauerte ein paar Wochenenden; die Analyse darauf einen Abend. Genau diese Umkehrung des Verhältnisses wollen wir Fertigungs- und Logistikteams geben, die sich keinen Data Hire leisten können.
Der Wert liegt nicht in der ersten Antwort. Die ist meistens der einfache Teil. Der Wert liegt darin, die nächsten vier günstig stellen zu können und sie weiterzustellen, wenn neue Daten ankommen. Genau darum geht es in dieser Football-Case-Study am Ende wirklich.
Shout out an Benjamin Turk, der den ursprünglichen LinkedIn-Post hinterfragt hat. Der größte Teil dieses Artikels existiert, weil er die erste Antwort nicht akzeptiert hat.